The Wall Street Journal’s Amir Efrati has raised eyebrows with an article (subscription required) saying Google is working to stay ahead of its rivals in Internet search by introducing more so-called “semantic search” technology. The idea is the Google’s search box wouldn’t just be a place for users to type keywords or specifically-formed queries, but a box that had an actual understanding of many of the terms, names, verbs, and references people type in — and could apply that knowledge to users’ searches. In theory, semantic search should be able to return results that reflect a searcher’s intent, and in some cases improve Google’s ability to give an answer right away without referring users off to another site.
But wait — is this anything new? Doesn’t Google already put some answers right up front? And how could semantic search potentially help Google maintain its lead in the Internet search business?
What is semantic search?
In a nutshell, semantic has much more in common with Watson, the IBM supercomputing application that handily defeated humans at Jeopardy! than it does with the Find dialog in Microsoft Word.
Loosely speaking, the world of computerized searching breaks down into two types:
Literal search (sometimes called navigational search) looks for exact matches for some or all of the terms entered, and returns matching items — whether files, Web pages, products, or some other discrete unit of information. Literal search can be augmented with things like stem-matching, conjugates, and association that expand or restrict the search in useful ways — so searching for “fly” might also hit “flight.” Literal search is what we’re most familiar with today, in part because it’s the easiest for computers to perform.
Semantic search differs from literal search in two ways. First, semantic search tries to understand what a user is asking in a query by placing it in context through analysis of the query’s terms and language. This analysis is conducted against tightly pre-compiled pools of knowledge, potentially including knowledge about the user. Second, instead of returning a set of files, Web pages, products, or other items, semantic search tries to provide a direct answer to a question. If you ask a semantic search engine “When was Pluto discovered?” it might answer “Pluto was discovered on February 18, 1930 by Clyde Tombaugh*,” where a literal search engine would most likely return links to Web pages that contain the words “discovered” and “Pluto.”
It turns out literal search and semantic search are good for different tasks. Literal search is great when a user is looking for a specific thing, whether that be a file, Web page, document, product, album, or other discrete item. Semantic search, on the other hand, turns out to be more useful when a user is looking for specific information — like a date, number, time, place, or name.
Thanks in part to the proliferation of literal search technology in everything from word processors to Web search engines, we’re most accustomed to literal search. Most of us already know how to manipulate literal search to get us closer to what we want on the first try. However, according to Efrati’s WSJ article, Google believes semantic search technology could provide direct answers to between 10 and 20 percent of Web searches. According to Comscore, Google handled 11.7 billion searches in the United States alone in February 2012. With semantic search capabilities, more than 2.3 billion of those searches could have been answered directly, instead of sending people off to other Web pages and sites.
Doesn’t Google already do this?
If you’ve used Google Web search at all you’re probably thinking “But wait, Google already does this!” Type “current time in Tokyo” or “how tall is Mount Everest” and Google will put its best guess at a precise answer at the top of its search results. Google even cites sources for its response, and some of those sources will be in the classic “ten blue links” below the answer. (Google reports Mount Everest is 8,848 meters tall, by the way.)
To be fair, this is one of just many useful capabilities Google has built into its search bar: It’ll do (sophisticated) math, perform unit and currency conversions, and pull up things like flight information and local movie show times — no need to type out a complicated query. It can also tap into some public data sources. For instance, typing “population Mexico” into the search box will display data from the World Bank. The response today is 113,423,047 people.
However, Google’s efforts to provide direct answers to some types of questions falls down pretty quickly, because those features are largely implemented as special cases to Google’s literal search engine, rather than as a semantic search that tries to understand what the user wants. Type “how tall is mt everest” (note the spelling) into the search box, and Google doesn’t even attempt to provide an answer: Google search doesn’t know “mt” means “mount.” Similarly, if Google has determined your current location is not in Mexico (and, if Google doesn’t have your location, it’ll guess by your IP address and, no, you can’t opt out) searching for “population mexico city” might return some unexpected results. Surely Mexico City is home to more than 10,852 people, right?
How semantic search is different
Semantic search tries to eliminate these sorts of gaffes in two ways. First, it tries to more accurately understand the intent behind a particular query. Second, it attempts to match the elements of that query against pre-compiled pools of deep knowledge to see if it can work out a meaningful answer.
When you send a query to a literal search engine like Google, it doesn’t instantaneously zip out to every site on the Internet, look them over, and report back a list of sites it thinks best match your terms. Instead, Google has software programs constantly scouring the Internet for new sites and new Web pages, which create an index from all the pages they find. Although this is a vast over-simplification, when users type in a search query like “Yalta conference,” Google looks at that index for pages that match both “Yalta” and “conference,” as well as pages that have both terms in proximity to one another (say, within 8 or 10 words). Google then collects the URLs for those pages, sorts by its internal PageRank (Google’s measure of a page’s relative merits that basically counts links to it as positive votes), and returns a list.
The data management and engineering behind a process like that is both daunting and mammoth, and Google deserves kudos for pulling it off — especially since Google is often able to do this in a fraction of a second. Similar things happen behind the scenes at Microsoft’s Bing.
A semantic search would approach the same query differently. Rather than comparing a query against a pre-compiled (and constantly-updated) index of Web pages it knows about, a semantic search engine compares the query against discrete, pre-complied knowledge sets it has available. Think of knowledge sets like databases: At heart, they’re full of data, facts, and figures about a particular subject. There are different kinds of knowledge sets. A couple interesting ones are ontologies (which represent formalized information that can be manipulated with rules, functions, and restrictions) and folksonomies, which usually represent collaboratively defined knowledge sets: Examples would be hashtagging and social bookmarks.

Knowledge sets are more than just storage bins. They also represent relationships between items in the knowledge base, and enable information to be meaningfully used across multiple knowledge sets. Furthermore, relationships are often expressed in such a way that accurate logical inferences can be made without having to store all the possible derivative data. This is anthropomorphizing a bit, but semantic search engines can perform basic reasoning and deduction on the data they know about. As part of that process, semantic search engines are often designed to assess a level of confidence they have in their derivations. If they don’t think they know what they’re talking about, they might stay mute. If they’re pretty sure, they’ll spit up an answer.
So if you input “Yalta conference” into a semantic search engine, it would look in its knowledge sets and probably spit up some basic facts and figures, perhaps “February 4 to 11, 1945.” It might indicate Stalin, Churchill, and Franklin Roosevelt attended, and it was an important even in the closing months of World War II. Pretty basic stuff.
If you ask a literal search engine “Did the Yalta Conference happen during the Korean War?” you’ll probably just get a list of ten blue links. One might have an answer.
However, if you ask a semantic search engine, you should get a one-word response: “No.”
That is where semantic search gets incredibly interesting.
Isn’t this Wolfram Alpha?
If these queries sound like the sorts of things people throw at the Wolfram Alpha search engine, you’re exactly right. Rather than being an index of Web pages, Wolfram Alpha attempts to be a knowledge engine. Wolfram Alpha isn’t about searching for a thing (like a Web page), but asking for an answer. Wolfram Alpha relies on pre-complied knowledge bases to produce its results, and the company is adding and updating new knowledge bases regularly. Some are highly specialized technical data — like information on chemical elements or the genome of the fruit fly — while others are more whimsical. For instance, Wolfram Alpha knows quite a lot about cat breeds.
So long as you stay within the realms of Wolfram Alpha’s knowledge, it can perform useful analysis of the data. For instance, Wolfram Alpha can compare the jumping distances of lions and tigers. (Turns out their comparable, but tigers seem to generally edge out lions.) But if you want to know how far kangaroos can jump? Oops, sorry: No data available.
But the failed query on kangaroo hops shows a bit about how Wolfram Alpha tries to understand things. Before it provides an answer, the engine indicates it’s assuming “kangaroo” means “kangaroos, wallabies,” but users can switch to the antilopine kangaroo, the red kangaroo, or the eastern grey kangaroo. Similarly, Wolfram Alpha has interpreted “how far can a kangaroo jump” to be a query for “jumping distance,” a specific data point it might have about animals. Turns out, Wolfram Alpha does not currently have that data, but its interpretation of the query is very important.
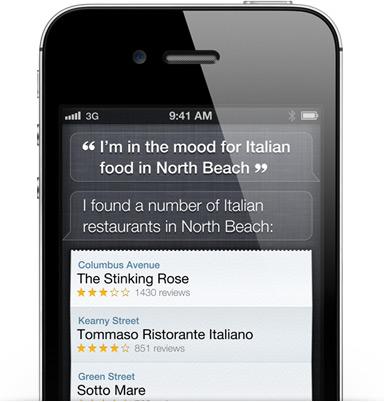
Isn’t this Siri?
If these queries sound like the sorts of things people throw at Siri in the iPhone 4S (but, remember, not the new iPad debuting this week), you’re exactly right. However, it’s important to remember that Siri only tackles one half of the equation: understanding user’s queries. In doing so, Siri takes on the very tough computing problem of accurately recognizing a user’s speech over a microphone in real time. That’s no small feat, but it isn’t a semantic search engine. Behind the scenes, Siri is handing off queries to Wolfram Alpha, Yelp, and (if all else fails) the user’s preferred Web search engine. If you ask Siri “Did the Yalta Conference happen during the Korean War,” it may accurately recognize what you’re asking — it did for me — but it’s just going to offer to do an old-school literal Web search for you.
What to expect
Google’s interest in semantic search is likely two-fold. First, it likely wants to use the technology as another bragging point that puts it ahead of its competition — mostly Microsoft Bing. Bing has long had a partnership with Wolfram Alpha designed to help the search engine deliver direct answers when possible. However, so far neither Bing nor Google have made major inroads with consumers with direct search results. After all, most everyday search users probably don’t know the (limited) capabilities already exist. Even for users who are aware of them, even Google seems to think the technology is only applicable to 10 to 20 percent of searches. That’s a lot of searches, but means the majority (80 to 90 percent) of searches won’t use it.
However, as consumers rapidly abandon notebooks, desktops, and traditional computing platforms, the capability to provide short, easily understood answers to complicated search queries could become very important in the mobile world. For users who are driving or otherwise not willing to fiddle with keypads or onscreen keyboards, the ability to response to spoken queries like “Is Golden Gate Park bigger than Central Park?” or “Which way to Malcolm’s flat?” with simple answers like “Yes,” and “Take the next left” could be invaluable differentiators for mobile platforms.
That is almost certainly where companies like Apple and Google are looking to take the technology.
* Tombaugh first identified Pluto as a moving object on February 18, 1930, but Pluto had been unwittingly spotted on several earlier occasions. The earliest currently known was in 1909. See? Knowledge is slippery.
Photo via: Annette Shaff / Shutterstock.com