
First the apocalyptic warning: We’re running out of data storage.
Chances are that this isn’t something you’ve had to worry about too much in recent years. There was a time, not all that long ago, when your computer’s finite hard drive was all the storage you had available. Hit that limit (which, in the case of my own first computer, was less than 100MB) and you resorted to floppy disks and other local external storage. When you ran out of that, too, you got deleting.
Each day, around 2.5 quintillion bytes of data is created, courtesy of the 3.7 billion humans who now use the internet.
We don’t delete any more. Nor do companies, especially those valued based on the data they own. Instead, we simply propel our files off to the cloud, whose very name is ephemeral and ethereal; lacking in any real physicality. Where is the data stored? It doesn’t matter so long as we can get it back. What are the perils of running out of cloud storage? Seemingly very little, besides having to up your monthly subscription payments to unlock more glorious free space.
As a result, the idea that we might one day run out of data storage is as hard to wrap your head around as the suggestion that we could run out water: that glorious free resource which falls from the sky. But 2018 is the year in which Cape Town, South Africa, came precipitously close to running out of water. And we could run out of data storage, too.
Data, data, everywhere
The reason for this is the unimaginable pace at which we currently produce data. Each day, around 2.5 quintillion bytes of data is created, courtesy of the 3.7 billion humans who now use the internet. In the last two years alone, a mind-boggling 90 percent of the world’s data has been created. With a growing number of smart devices connected to the Internet of Things, that figure is set to increase significantly.
“When we think of cloud storage, we think of these infinite stores of data,” Hyunjun Park, CEO and co-founder of the data storage company Catalog, told Digital Trends. “But the cloud is really just someone else’s computer. What most people don’t realize is that we’re generating so much data that the pace at which we are generating it is far outpacing our ability to store all of it. In the very near future, we’re going to have a huge gap between the useful data that we’re generating, and how we are able to store it using conventional mediums.”
Catalog has developed technology they believe could transform the way we store data.
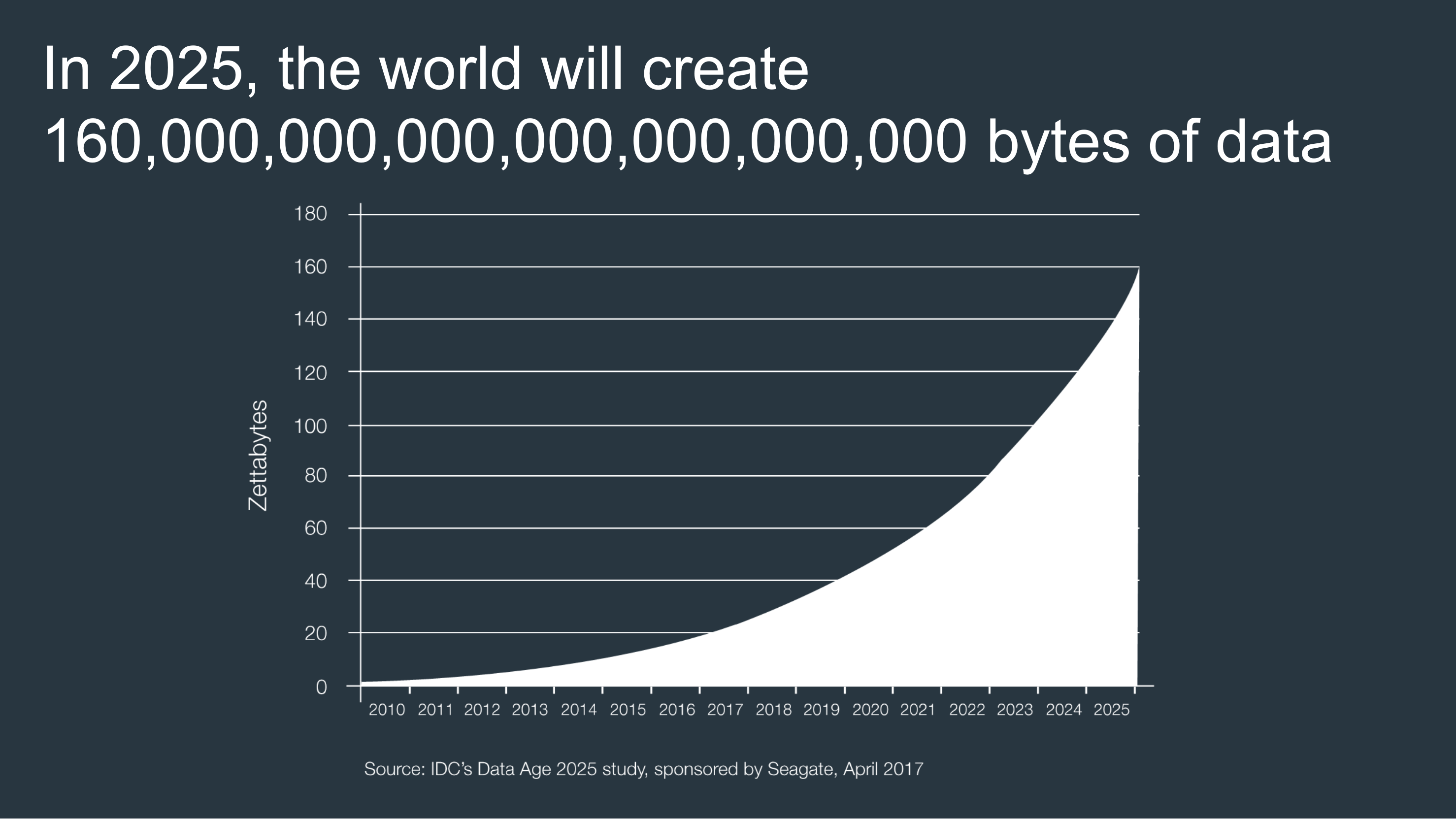
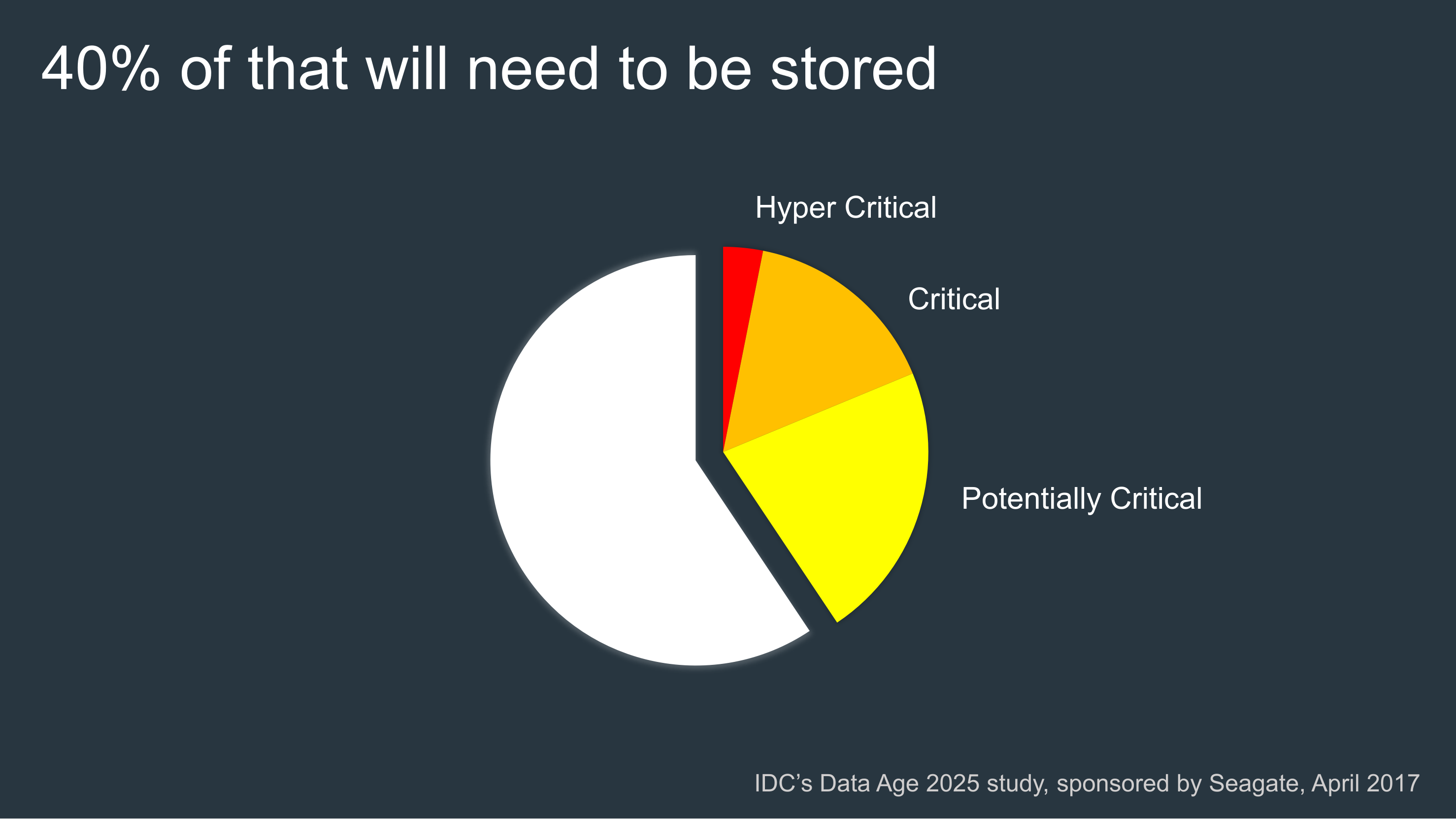
Since cloud storage companies are busy building new data centers, and expanding their existing ones, at a rate of knots, it’s difficult to work out when we could run out of data storage capacity. There’s no movie-style countdown clock. According to Park, however, as early as 2025 humankind may have produced more than 160 zettabytes of data cumulatively. (A zettabyte, in case you’re wondering, is a trillion gigabytes.) How much of this will we be able to store? Around 12.5 percent of it, Park suggests.
Clearly, something needs to be done.
Is DNA the answer?
That’s where Park and fellow MIT scientist and co-founder Nathaniel Roquet enter the picture. Their startup Catalog has developed technology they believe could transform data storage as we know it; allowing, or so they claim, the entirety of the world’s data to be comfortably fit into a space the size of a coat closet.

Catalog’s solution? By encoding data into DNA. That might sound like the plot of a Michael Crichton novel, but their scalable and affordable solution is serious, and has so far received $9 million in venture funding — along with the support of leading professors from Stanford and Harvard Universities.
“A question I get asked often is, ‘Whose DNA are we using?’” Park laughed. “People are afraid of us taking DNA from people and turning them into mutants, or things like that.”
For years bottlenecks have stopped DNA from living up to it’s massive data storage potential.
This is not, we should make clear, what Catalog is doing. The DNA the company is coding data into is a synthetic polymer. It is not something that comes from a biological origin, and the series of base pairs into which the data is coded, as a series of ones and zeros, isn’t the code for anything living. But the end product is nonetheless biologically indistinguishable from something you might find in a living cell.
The idea of DNA being a potential storage method has been speculated upon for decades now, virtually since James Watson and Francis Crick discovered the double helix in 1953. However, until now there have been a number of bottlenecks that have stopped it living up to its massive potential as a computational data storage solution.
Traditional thinking on DNA-based data storage focused on the synthesis of new DNA molecules; mapping the sequence of bits to the sequence of DNA’s four base pairs and making enough molecules to represent all of the numbers you want to store. The problem is that this process is slow and expensive, both considerable bottlenecks when it comes to storing data.
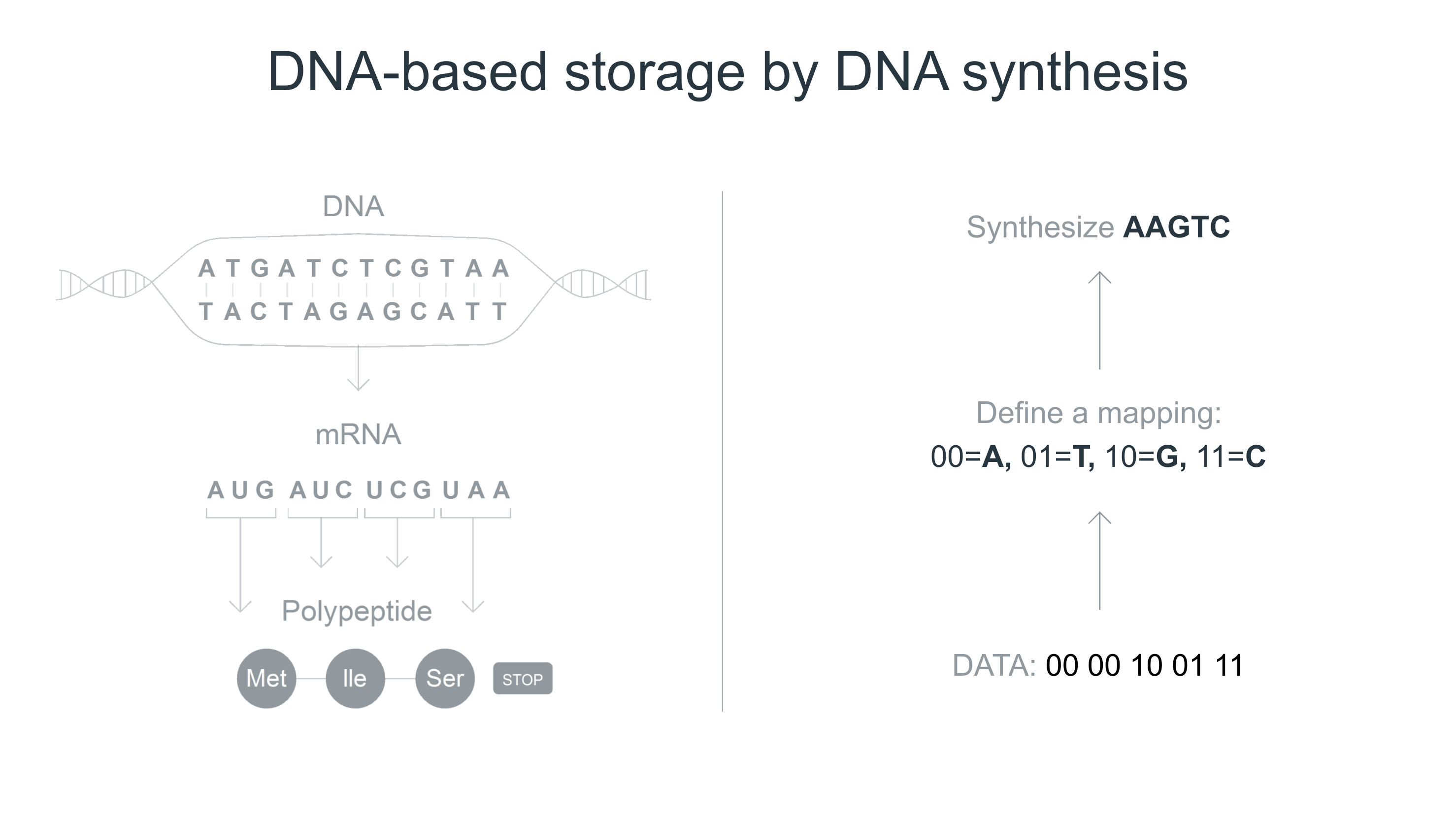
Catalog’s approach is based on decoupling the synthesis process from the encoding process. Essentially, the company generates massive numbers of just a few different molecules (making it much cheaper) and then encodes the information by generating huge diversity from the premade molecules.
As an analogy, Catalog likened the previous approach to manufacturing custom hard drives with all your data hard-wired in. Storing different data means building a whole new hard drive from the ground up. Their approach, they suggest, is akin to mass-producing blank hard drives, and then filling it with the encoded information as and when required.
It’s all about the storage
The exciting part of all of this is the mind-boggling amount of data it can store. As a proof of concept, Catalog has used its technology to encode books like The Hitchhiker’s Guide to the Galaxy into DNA. But that’s nothing compared to the possibilities.
From start to finish, reading data off of DNA will take a minimum of several hours.
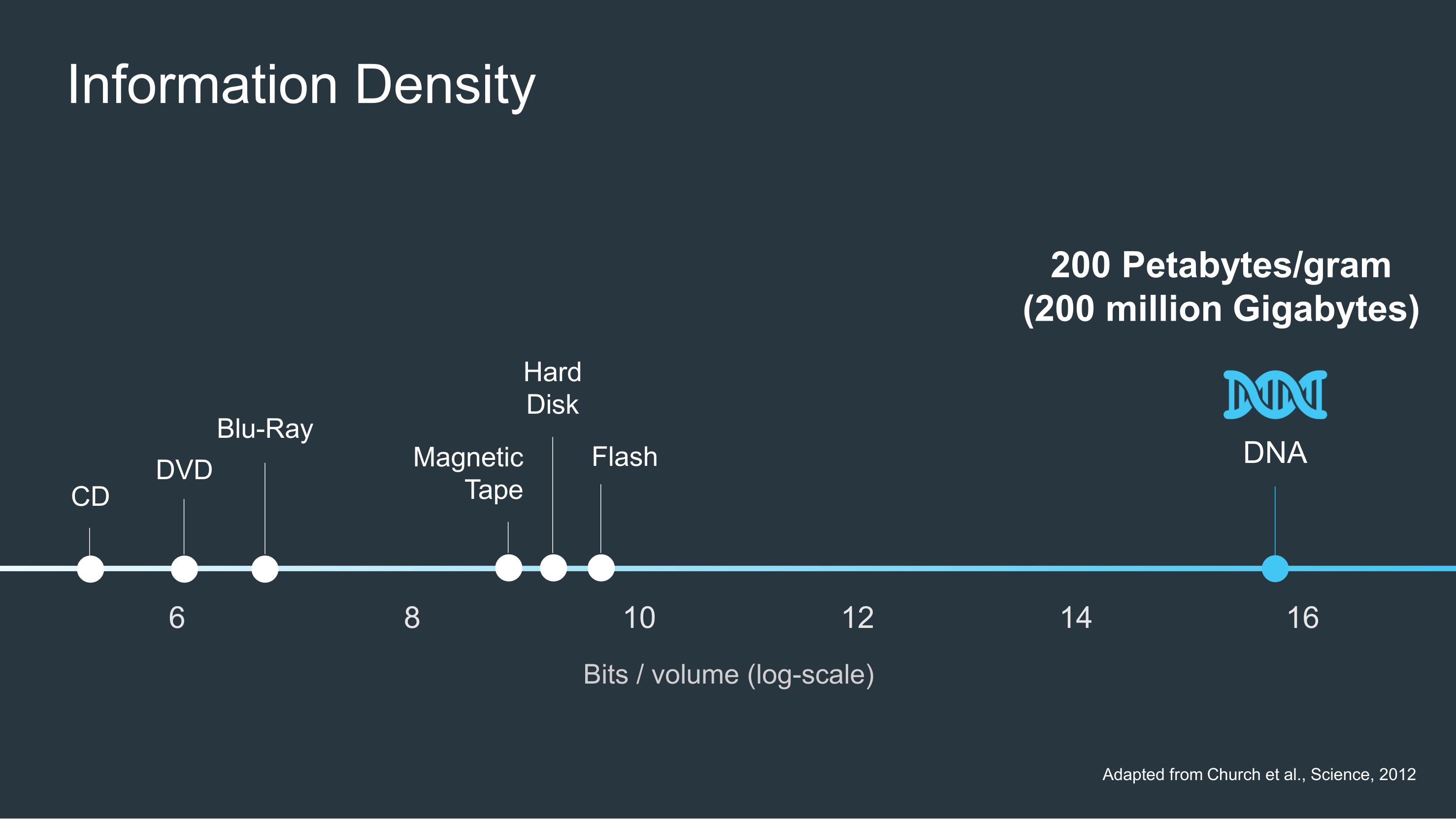
“If you’re comparing apples to apples, the bits you can store in the same volume comes out at something like 1 million times the informational density of a solid-state drive,” Park said. “Whatever you can store in a flash drive, you could store 1 million times that in the same volume if you’re doing it in DNA.”
The comparison with solid-state drives is not exact, however. DNA may be able to store far more information in the same volume, but it doesn’t have the instant access of, say, a USB-connected flash drive. Catalog’s approach transforms data into a solid pellet of synthetic polymer.
To access your data, scientists would need to take said pellet, rehydrate it by adding water, and then read it using a DNA sequencer. This provides the base pairs of the DNA, which can, in turn, then be used to calculate the ones and zeroes that reassemble your data. From start to finish, the process will take a minimum of several hours.

For this reason, Catalog is initially targeting a market used to these kinds of delays: the archiving market. This is the kind of data that is currently stored on formats like magnetic tape, used for keeping track of the kind of information that you might hope not to have to revisit, but is still crucial to hang onto. (Imagine the corporate equivalent of the warranty to your fridge.)
But is there ever a point at which this will matter to the average user? After all, as we pointed out at the top of this article, most of us don’t really think all that much about our data and where it is kept. Is it on magnetic tape? Is it on solid-state storage? We don’t mind so long as it is there when we need it.
DNA-based data encoding is likely to be a long-term storage option, while short-term data takes other forms.
Because of the amount of time it takes to retrieve information, there’s unlikely to ever be a point at which, for instance, your Google Cloud information is stored in enormous vats of DNA or as a series of marble-like pellets in Mountain View, CA. Should Catalog be able to prove its concept to businesses, this is likely to be a long-term storage option, while short-term data takes other forms.
Imagine the possibilities
There are exciting sci-fi-sounding possibilities, though. “Imagine a subcutaneous pellet containing all your health data, all your MRA scans, your blood tests, your X-rays from your dentist,” Park said. “You would always want that data to be very accessible to you, but you don’t necessarily want it up in the cloud somewhere, or on an unsecured server in a hospital. If you had that with you in the form of DNA, you could physically control that data and access to it, while making sure that only the authorized doctors could have access to it.”
After all, as he points out, all hospitals today have DNA sequencers. “I’m not saying we’re pursuing that right now, but it’s a possible future,” he said.
Having announced their new company to the world, Catalog is now focused on carrying out some pilot projects to demonstrate how this technology can be used effectively. “These aren’t scientific challenges we have left to solve, but rather mechanical optimization problems,” he noted.
Having, by his own admission, having entered this field because it sounded like a cool technological approach to a big problem, Park is now convinced that DNA data storage may turn out to be one of the most important technologies of our time.
Heck, when it comes to being able to archive human history as we know it, it’s hard to disagree. “It’s about preserving our way of life as we know it,” he explained.



